ProcessPool¶
- author
Krzysztof Daniel Ciba <Krzysztof.Ciba@NOSPAMgmail.com>
- date
Tue, 8th Jul 2012
- version
second and final
The ProcessPool creates a pool of worker sub-processes to handle a queue of tasks much like the producers/consumers paradigm. Users just need to fill the queue with tasks to be executed and worker tasks will execute them.
To construct ProcessPool one first should call its constructor:
pool = ProcessPool( minSize, maxSize, maxQueuedRequests, strictLimits=True, poolCallback=None, poolExceptionCallback=None )
where parameters are:
- param int minSize
at least <minSize> workers will be alive all the time
- param int maxSize
no more than <maxSize> workers will be alive all the time
- param int maxQueuedRequests
size for request waiting in a queue to be executed
- param bool strictLimits
flag to kill/terminate idle workers above the limits
- param callable poolCallback
pool owned results callback
- param callable poolExceptionCallback
pool owned exception callback
In case another request is added to the full queue, the execution will lock until another request is taken out. The ProcessPool will automatically increase and decrease the pool of workers as needed, of course not exceeding above limits.
To add a task to the queue one should execute:
pool.createAndQueueTask( funcDef,
args = ( arg1, arg2, ... ),
kwargs = { "kwarg1" : value1, "kwarg2" : value2 },
taskID = taskID,
callback = callbackDef,
exceptionCallback = exceptionCallBackDef,
usePoolCallbacks = False,
timeOut = 0,
blocking = True )
or alternatively by using ProcessTask instance:
task = ProcessTask( funcDef,
args = ( arg1, arg2, ... )
kwargs = { "kwarg1" : value1, .. },
callback = callbackDef,
exceptionCallback = exceptionCallbackDef,
usePoolCallbacks = False,
timeOut = 0,
blocking = True )
pool.queueTask( task )
where parameters are:
- param callable funcDef
callable py object definition (function, lambda, class with __call__ slot defined)
- param list args
argument list
- param dict kwargs
keyword arguments dictionary
- param callable callback
callback function definition (default None)
- param callable exceptionCallback
exception callback function definition (default None)
- param bool usePoolCallbacks
execute pool callbacks, if defined (default False)
- param int timeOut
time limit for execution in seconds (default 0 means no limit)
- param bool blocking
flag to block queue until task is en-queued
The callback, exceptionCallback, usePoolCallbacks, timeOut and blocking parameters are all optional. Once task has been added to the pool, it will be executed as soon as possible. Worker sub-processes automatically return the result of the task. To obtain those results one has to execute:
pool.processRequests()
This method will process the existing return values of the task, even if the task does not return anything. This method has to be called to clean the result queues. To wait until all the requests are finished and process their result call:
pool.processAllRequests()
This function will block until all requests are finished and their result values have been processed.
It is also possible to set the ProcessPool in daemon mode, in which all results are automatically processed as soon they are available, just after finalization of task execution. To enable this mode one has to call:
pool.daemonize()
To monitor if ProcessPool is able to execute a new task one should use ProcessPool.hasFreeSlots() and ProcessPool.isFull(), but boolean values returned could be misleading, especially if en-queued tasks are big.
Callback functions¶
There are two types of callbacks that can be executed for each tasks: exception callback function and results callback function. The first one is executed when unhandled exception has been raised during task processing, and hence no task results are available, otherwise the execution of second callback type is performed. The callback functions can be defined on two different levels:
directly in ProcessTask, in that case those have to be shelvable/picklable, so they should be defined as global functions with the signature:
callback( task, taskResult )where task is a ProcessPool.ProcessTask reference and taskResult is whatever task callable is returning for results callback and:
exceptionCallback( task, exc_info)where exc_info is a S_ERROR dictionary extended with “Exception”: { “Value” : exceptionName, “Exc_info” : exceptionInfo }
in the ProcessPool itself, in that case there is no limitation on the function type: it could be a global function or a member function of a class, signatures are the same as before.
The first types of callbacks could be used in case various callable objects are put into the ProcessPool, so you probably want to handle them differently depending on their definitions, while the second types are for executing same type of callables in sub-processes and hence you are expecting the same type of results everywhere.
If both types of callbacks are defined, they will be executed in the following order: task callbacks first, pool callbacks afterwards.
Timed execution¶
One can also put a time limit for execution for a single task, this is done by setting timeOut argument in ProcessTask constructor to some integer value above 0. To use this functionality one has to make sure that underlying code is not trapping SIGALRM, which is used internally to break execution after timeOut seconds.
Finalization procedure¶
The finalization procedure is not different from Unix shutting down of a system, first ProcessPool puts a special bullet tasks to pending queue, used to break WorkingProcess.run main loop, then SIGTERM is sent to all still alive sub-processes. If some of them are not responding to termination signal, ProcessPool waits a grace period (timeout) before killing of all children by sending SIGKILL.
To use this procedure one has to execute:
pool.finalize( timeout = 10 )
where timeout is a time period in seconds between terminating and killing of sub-processes. The ProcessPool instance can be cleanly destroyed once this method is called.
WorkingProcess life cycle¶
The ProcessPool is creating workers on demand, checking if their is not exceeding required limits. The pool worker life cycle is managed by WorkingProcess itself.
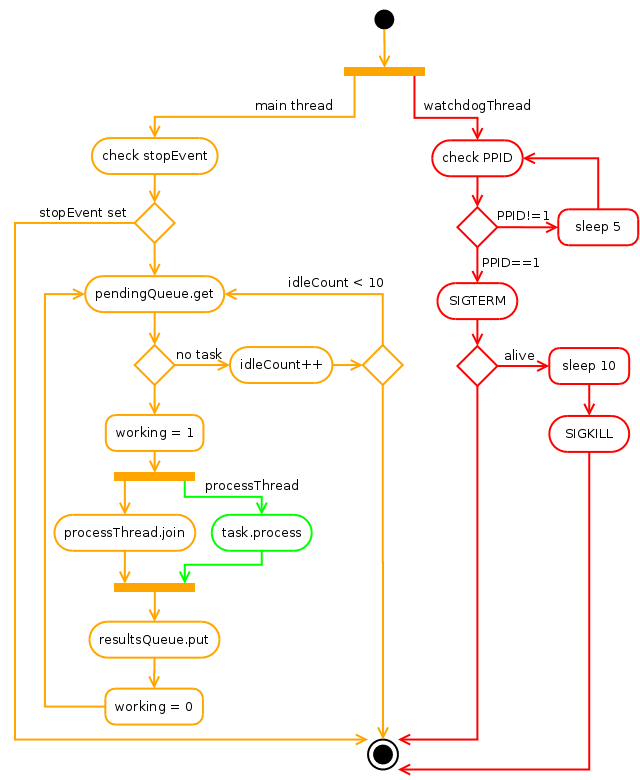
Once created worker is spawing a watchdog thread checking on every 5 seconds PPID of worker. If parent process executing ProcessPool instance is dead for some reason (an so the PPID is 1, as orphaned process is adopted by init process), watchdog is sending SIGTERM and SIGKILL signals to the worker main thread in interval of 30 seconds, preventing too long adoption and closing worker life cycle to save system resources.
Just after spawning of a watchdog, the main worker thread starts also to query input task queue. After ten fruitless attempts (when task queue is empty), it is commiting suicide emptying the ProcessPool worker’s slot.
When input task queue is not empty and ProcessTask is successfully read, WorkingProcess is spawning a new thread in which task processing is executed. This task thread is then joined and results are put to the results queue if they are available and ready. If task thread is stuck and task timout is defined, WorkingProcess is stopping task thread forcefully returning S_ERROR( ‘Timed out’) to the ProcessPool results queue.